Introduction to Clustering in Machine Learning
Clustering is a type of unsupervised learning used in machine learning to group similar data points together. In fields like Data Science and AI, clustering helps discover hidden patterns in data without predefined labels. It is widely used in analyzing large datasets using Python tools.
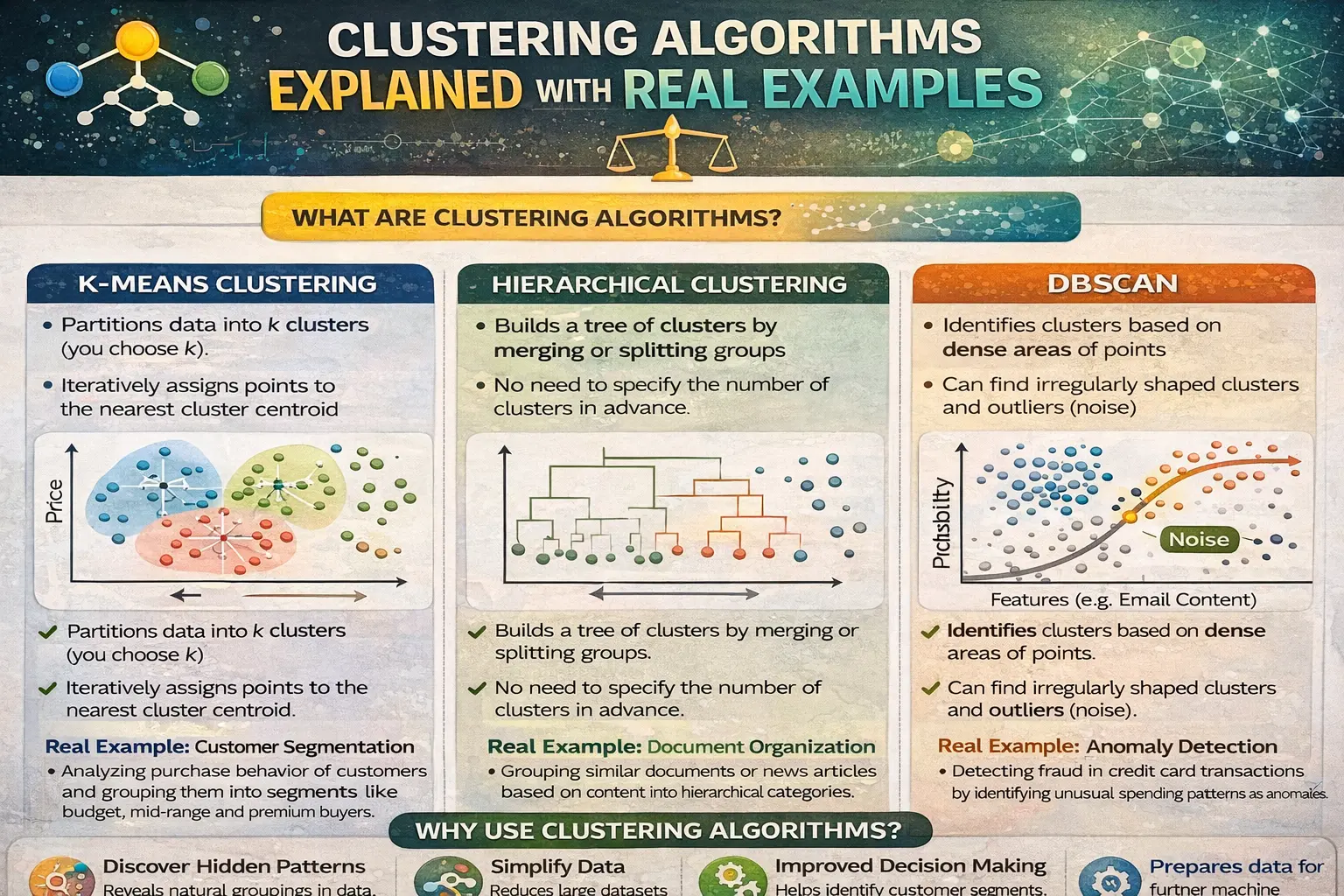
What are Clustering Algorithms
Clustering algorithms are techniques that divide data into groups or clusters based on similarities. In data analytics, these algorithms help organize data in a meaningful way, making it easier to understand patterns and relationships within datasets.
How Clustering Works
Clustering works by measuring the similarity between data points using distance metrics such as Euclidean distance. In machine learning, the algorithm groups data points that are closer to each other into the same cluster. This process helps simplify complex datasets.
Types of Clustering Algorithms
There are several types of clustering algorithms, including K-Means, Hierarchical Clustering, and DBSCAN. In Data Science, each method is used based on the nature of the data and the problem being solved. These algorithms provide flexibility in handling different kinds of datasets.
K-Means Clustering Explained
K-Means is one of the most popular clustering techniques. It divides data into a fixed number of clusters by assigning each data point to the nearest cluster center. In data analytics, it is commonly used for customer segmentation and pattern recognition using Python.
Hierarchical Clustering Explained
Hierarchical clustering builds a tree-like structure of clusters. It can be either agglomerative or divisive. In machine learning, this method is useful for understanding relationships between data points and visualizing cluster structures.
DBSCAN Clustering Explained
DBSCAN is a density-based clustering algorithm that groups data points based on density. It is effective in identifying clusters of different shapes and detecting outliers. In Data Science, it is widely used when dealing with noisy datasets.
Real-World Example: Customer Segmentation
One of the most common applications of clustering is customer segmentation. Businesses use clustering algorithms to group customers based on behavior, preferences, and purchase history. In AI systems, this helps companies create targeted marketing strategies and improve customer experience.
Real-World Example: Image Segmentation
Clustering is also used in image processing to segment images into different regions. In machine learning, this technique helps in identifying objects and patterns within images, making it useful for applications like facial recognition and medical imaging.
Advantages of Clustering Algorithms
Clustering algorithms are useful for exploring data and identifying hidden patterns. In data analytics, they help simplify complex datasets and provide valuable insights. They are flexible and can be applied to various domains in Data Science.
Limitations of Clustering Techniques
Despite their benefits, clustering algorithms have some limitations. Choosing the right number of clusters can be challenging, and results may vary depending on the method used. In machine learning, proper evaluation and validation are necessary to ensure accurate results.
Integration with Visualization Tools
Clustering results can be visualized using charts and graphs to better understand patterns. In Power BI, clustered data can be displayed through dashboards, making it easier to interpret insights in data analytics projects.
Conclusion: Importance of Clustering in Data Science
Understanding clustering algorithms is essential for anyone working in Data Science, AI, Power BI, machine learning, data analytics, and Python. These techniques help uncover patterns, improve decision-making, and solve real-world problems. By learning clustering, beginners can enhance their skills and work effectively with complex datasets.