Introduction to Clustering Techniques in Data Science
Clustering is an essential concept in modern analytics where data is grouped based on similarity. In fields like Data Science and machine learning, clustering helps uncover hidden patterns without labeled data. Two of the most popular clustering techniques are K-Means and Hierarchical Clustering. Both methods are widely used in data analytics to segment customers, detect anomalies, and improve decision-making processes. Understanding their differences is crucial for anyone working with Python-based data projects.
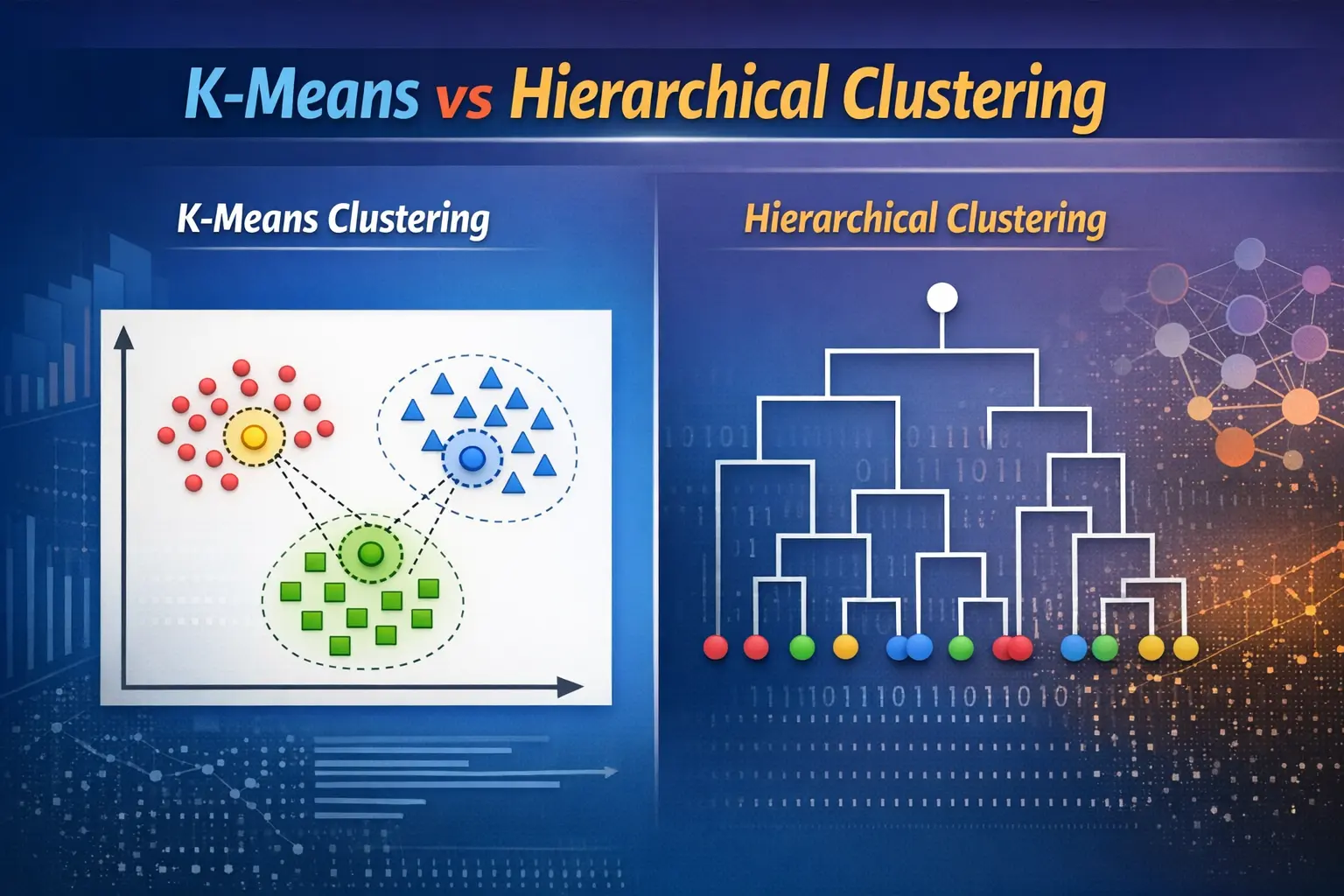
What is K-Means Clustering?
K-Means Clustering is a partition-based algorithm that divides a dataset into a predefined number of clusters. It works by assigning data points to the nearest centroid and recalculating centroids iteratively. This approach is highly efficient and commonly used in AI applications where large datasets are involved. In practical scenarios, tools like Power BI and Python libraries make it easier to implement K-Means for visualization and analysis.
What is Hierarchical Clustering?
Hierarchical Clustering builds a tree-like structure called a dendrogram to represent data relationships. Unlike K-Means, it does not require specifying the number of clusters in advance. This method is widely used in Data Science when the goal is to understand the data structure deeply. It plays an important role in machine learning tasks where interpretability and relationships between data points matter more than speed.
Key Differences Between K-Means and Hierarchical Clustering
The primary difference lies in their approach. K-Means is fast and suitable for large datasets, while Hierarchical Clustering is more detailed but computationally expensive. In data analytics, K-Means is preferred when scalability is important, whereas Hierarchical methods are chosen for smaller datasets where insights are more critical. Both techniques can be implemented using Python, making them accessible for beginners and professionals alike.
Advantages of K-Means Clustering
K-Means is simple, easy to implement, and computationally efficient. It performs well with large datasets and is widely used in AI and machine learning applications such as customer segmentation and recommendation systems. Integration with tools like Power BI also allows users to visualize clustering results effectively, enhancing business intelligence processes.
Advantages of Hierarchical Clustering
Hierarchical Clustering provides a clear visualization of data relationships through dendrograms. It is highly useful in data analytics when the number of clusters is unknown. This method is often applied in Data Science research and biological data analysis, where understanding hierarchical relationships is essential. It works well with smaller datasets and offers more flexibility compared to K-Means.
Use Cases of K-Means vs Hierarchical Clustering
K-Means is commonly used in market segmentation, fraud detection, and image compression within AI-driven systems. On the other hand, Hierarchical Clustering is applied in gene analysis, document classification, and social network analysis. Both techniques are integral parts of machine learning workflows and are frequently implemented using Python for real-world problem solving.
When to Choose K-Means or Hierarchical Clustering
Choosing between these two depends on your data and objective. If you are working on large-scale data analytics projects and need faster results, K-Means is the better option. However, if your goal is to explore data structure and relationships in detail, Hierarchical Clustering is more suitable. Professionals in Data Science often use a combination of both methods to achieve optimal results.
Conclusion: Selecting the Right Clustering Method
Both K-Means and Hierarchical Clustering have their own strengths and limitations. In the world of Data Science and AI, selecting the right algorithm depends on the nature of your dataset and business goals. By leveraging tools like Power BI and programming languages such as Python, analysts can effectively apply these clustering techniques to gain meaningful insights and improve decision-making in data-driven environments.