Introduction to Bias-Variance Tradeoff in Data Science
The bias-variance tradeoff is a fundamental concept in Data Science that helps in understanding how machine learning models perform. It explains the balance between underfitting and overfitting, which directly impacts model accuracy. In real-world data analytics projects, achieving the right balance is crucial for building models that generalize well. This concept is widely used in Python-based workflows where model performance is continuously optimized
What is Bias in Machine Learning?
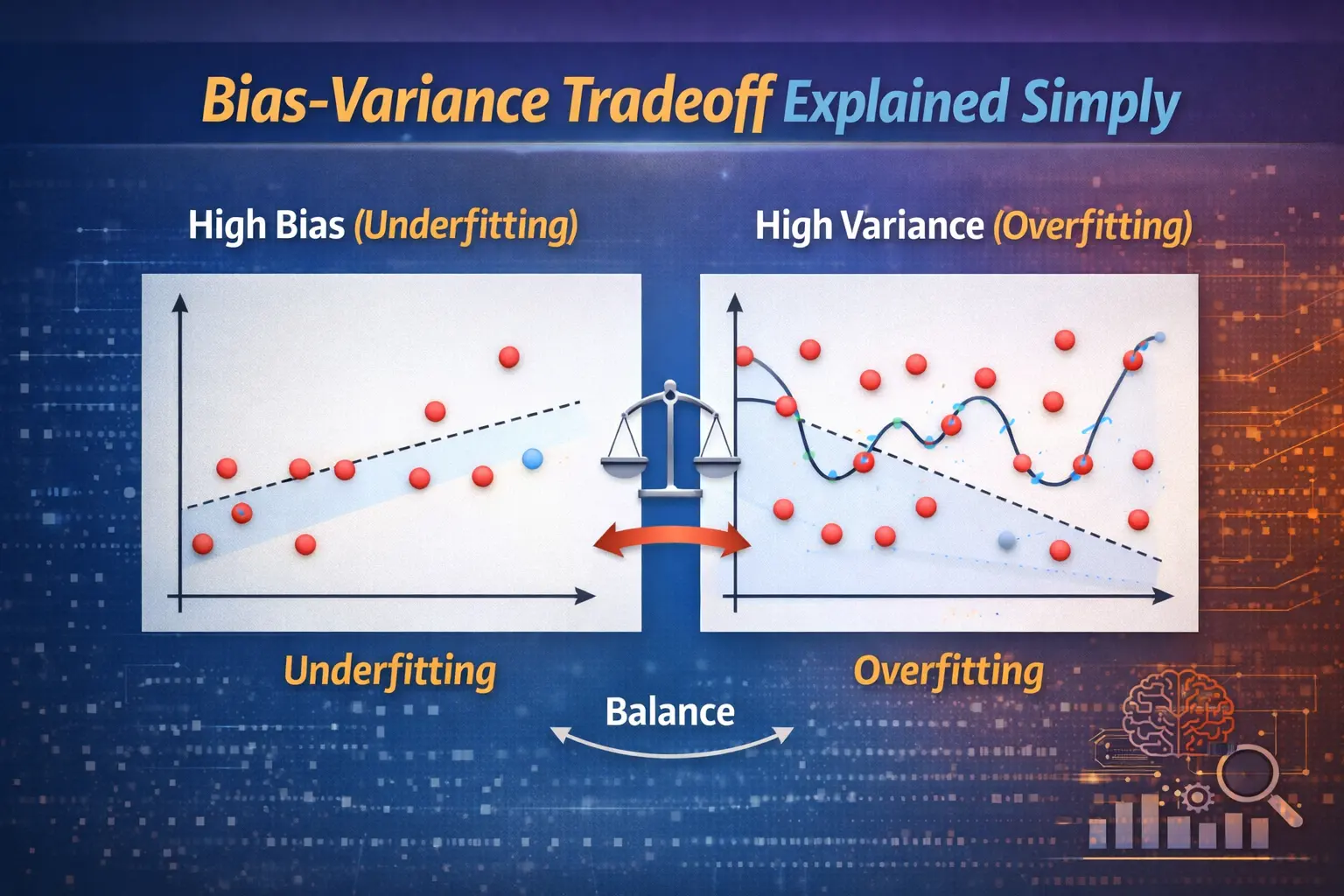
Bias refers to the error that occurs when a model makes overly simplified assumptions about the data. In machine learning, high bias can cause underfitting, meaning the model fails to capture important patterns. This is common in simple algorithms that cannot adapt well to complex datasets. In AI applications, reducing bias is essential to ensure the model learns meaningful relationships from data.
What is Variance in Data Analytics?
Variance refers to how much a model’s predictions change when trained on different datasets. A model with high variance pays too much attention to training data and captures noise instead of actual patterns. In data analytics, this leads to overfitting, where the model performs well on training data but poorly on unseen data. Using Python tools, developers often apply techniques to reduce variance and improve model stability.
Understanding the Bias-Variance Tradeoff
The bias-variance tradeoff is about finding the right balance between bias and variance to minimize overall error. In Data Science, a model with low bias and low variance is ideal but difficult to achieve. Increasing model complexity reduces bias but increases variance, while simplifying the model does the opposite. This balance is a key consideration in machine learning and AI model development.
Underfitting vs Overfitting Explained
Underfitting happens when a model has high bias and cannot capture the underlying trends in data. Overfitting occurs when a model has high variance and memorizes the training data instead of learning patterns. In data analytics, both situations are undesirable. Professionals use tools like Power BI to visualize model performance and identify whether a model is underfitting or overfitting.
How to Reduce Bias and Variance
There are several techniques to manage bias and variance effectively. To reduce bias, more complex models or additional features can be used. To reduce variance, techniques like regularization, cross-validation, and increasing training data are applied. In machine learning, these strategies are often implemented using Python libraries, making it easier to fine-tune models for better performance.
Real-World Applications of Bias-Variance Tradeoff
The bias-variance tradeoff plays a vital role in applications like recommendation systems, fraud detection, and predictive analytics. In AI systems, balancing bias and variance ensures accurate predictions and reliable performance. In Data Science projects, professionals continuously adjust models to maintain this balance and improve outcomes in data analytics tasks.
Importance of Model Selection and Evaluation
Choosing the right model depends heavily on understanding the bias-variance tradeoff. In machine learning workflows, evaluating models using validation data helps identify whether adjustments are needed. Tools like Power BI assist in presenting insights clearly, enabling better decision-making. This concept is especially important in Data Science, where accuracy and reliability are key priorities.
Conclusion: Achieving the Right Balance
The bias-variance tradeoff is essential for building effective machine learning models. In the world of AI and Data Science, finding the right balance ensures that models perform well on both training and unseen data. By leveraging tools like Python and Power BI, professionals can optimize their models and enhance overall data analytics performance.