Introduction to Ensemble Learning in Data Science
Ensemble learning is a powerful technique used in Data Science to improve model performance by combining multiple models. Instead of relying on a single algorithm, ensemble methods aggregate predictions to produce more accurate and stable results. In modern machine learning workflows, this approach is widely used to handle complex datasets and improve predictive accuracy in data analytics projects.
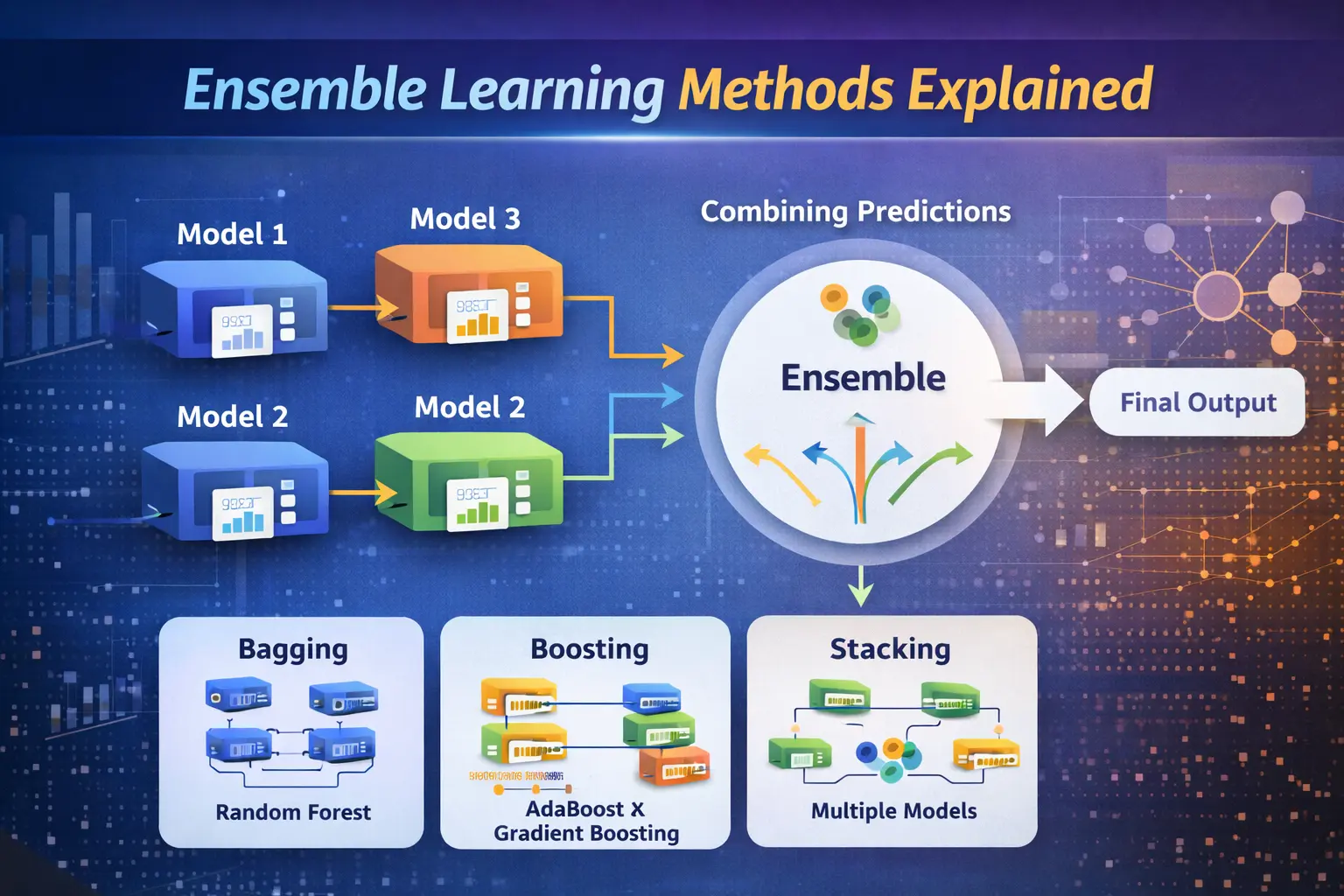
What is Ensemble Learning?
Ensemble learning refers to the process of combining multiple models, often called base learners, to solve a single problem. In AI systems, this technique reduces errors by balancing the weaknesses of individual models. Using tools like Python, developers can easily build ensemble models that perform better than standalone algorithms, especially in large-scale data analytics applications.
Types of Ensemble Learning Methods
There are three main types of ensemble methods: bagging, boosting, and stacking. Bagging focuses on reducing variance, boosting aims to reduce bias, and stacking combines multiple models to improve predictions. In machine learning, these techniques are widely applied to enhance model performance. They are essential tools in Data Science for building robust predictive systems.
Bagging: Reducing Variance in Models
Bagging, or Bootstrap Aggregating, involves training multiple models on different subsets of data and combining their outputs. This method is highly effective in reducing overfitting and improving stability. In data analytics, bagging is commonly implemented using Python libraries such as Random Forest, making it a popular choice for handling large datasets.
Boosting: Improving Model Accuracy
Boosting is an iterative technique where models are trained sequentially, each focusing on correcting the errors of the previous one. In AI applications, boosting algorithms like AdaBoost and Gradient Boosting are widely used for their high accuracy. Integration with tools like Power BI helps visualize model performance, making boosting a valuable method in business intelligence and machine learning projects.
Stacking: Combining Multiple Models
Stacking involves combining different types of models and using another model to make the final prediction. This approach leverages the strengths of multiple algorithms to achieve better results. In Data Science, stacking is often used in advanced projects where maximizing accuracy is critical. It works efficiently with Python frameworks designed for complex data analytics tasks.
Advantages of Ensemble Learning
Ensemble learning offers several benefits, including improved accuracy, reduced overfitting, and better generalization. In machine learning, it helps create models that perform consistently across different datasets. This approach is widely used in AI-driven systems and is supported by tools like Power BI for clear visualization and reporting in data analytics.
Limitations of Ensemble Methods
Despite its advantages, ensemble learning can be computationally expensive and complex to implement. Training multiple models requires more time and resources compared to single algorithms. In Data Science projects, managing these complexities is important, especially when working with large datasets using Python-based environments.
Real-World Applications of Ensemble Learning
Ensemble methods are widely used in various industries, including finance, healthcare, and e-commerce. In data analytics, they help in fraud detection, recommendation systems, and risk analysis. AI systems rely heavily on ensemble learning to deliver accurate predictions, making it a key component of modern machine learning solutions.
Conclusion: Why Ensemble Learning Matters
Ensemble learning plays a crucial role in improving model performance in Data Science and AI. By combining multiple models, it enhances accuracy and reliability in machine learning tasks. With the support of tools like Python and Power BI, professionals can implement ensemble methods effectively and unlock deeper insights in data analytics projects.