Introduction to Support Vector Machines in Data Science
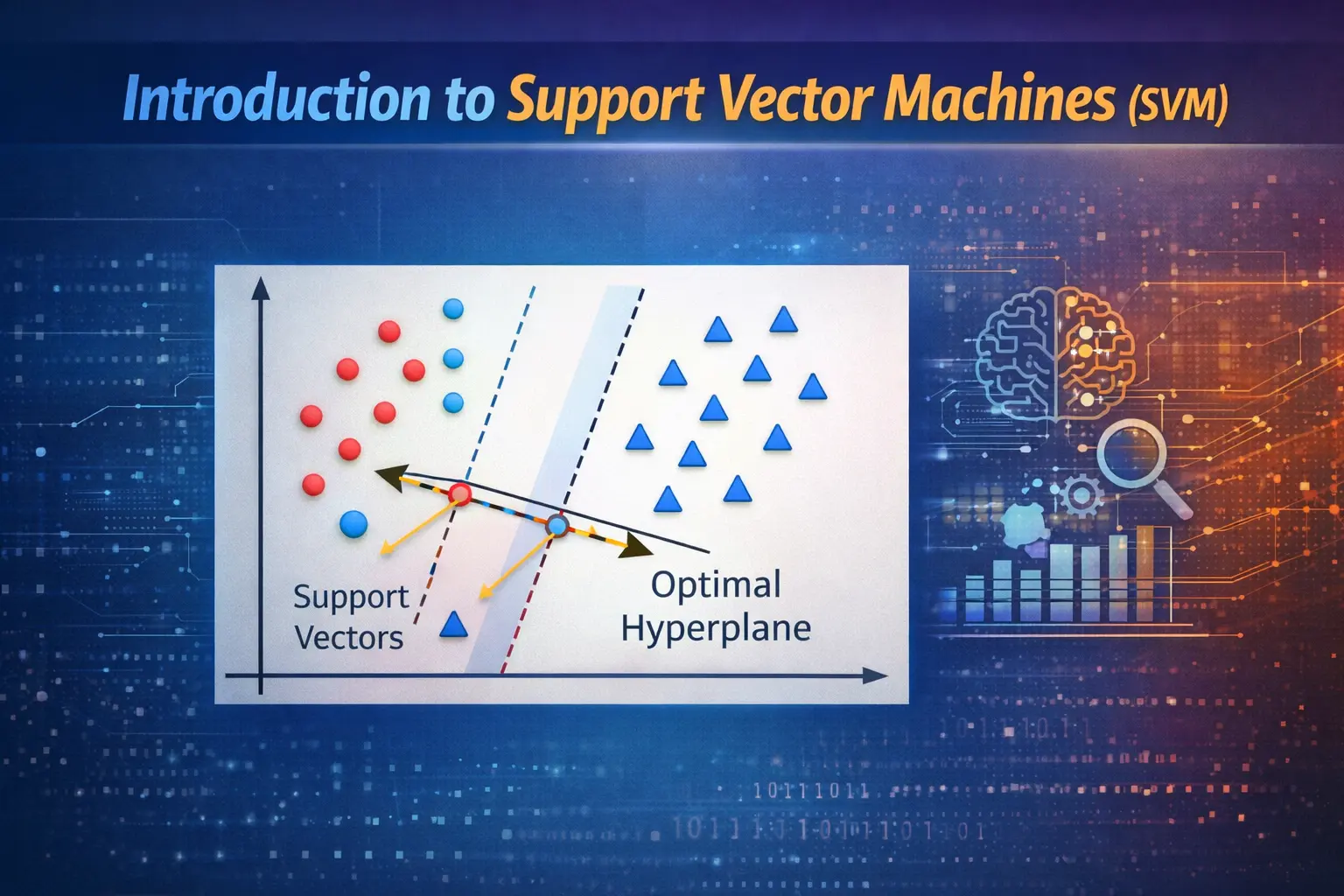
Support Vector Machines, commonly known as SVM, are powerful supervised learning algorithms used for classification and regression tasks. In the fields of Data Science and machine learning, SVM is widely appreciated for its ability to handle complex datasets and deliver accurate results. It works by finding the optimal boundary that separates different classes in the data, making it a reliable method in modern data analytics workflows.
Understanding the Working Concept of SVM
The core idea behind SVM is to find a hyperplane that best divides a dataset into different classes. In AI applications, this hyperplane maximizes the margin between data points of different classes, ensuring better generalization. Tools like Python libraries make it easier to implement SVM models, allowing data professionals to experiment with different kernels and parameters for improved performance.
Types of Support Vector Machines
SVM can be categorized into two main types: linear SVM and non-linear SVM. Linear SVM is used when data can be separated using a straight line, while non-linear SVM uses kernel functions to handle complex relationships. In machine learning projects, choosing the right type depends on the dataset structure. These techniques are frequently used in Data Science to solve both simple and advanced classification problems.
Kernel Functions in SVM
Kernel functions play a crucial role in transforming data into higher dimensions, where it becomes easier to separate classes. Common kernels include linear, polynomial, and radial basis function (RBF). In data analytics, kernels help SVMs adapt to different types of data distributions. With the help of Python frameworks, implementing these kernels becomes efficient and scalable for real-world AI applications.
Advantages of Support Vector Machines
SVM offers several advantages, including high accuracy, effectiveness in high-dimensional spaces, and robustness against overfitting. It is widely used in AI-driven systems where precision is critical. Integration with tools like Power BI helps visualize classification outcomes, making it easier for businesses to interpret results and make data-driven decisions.
Limitations of SVM
Despite its strengths, SVM also has some limitations. It can be computationally intensive for very large datasets and may require careful parameter tuning. In Data Science projects, selecting the right kernel and parameters can be challenging. However, with proper use of machine learning techniques and Python libraries, these challenges can be managed effectively.
Real-World Applications of SVM
Support Vector Machines are widely used in various industries, including image recognition, text classification, and bioinformatics. In data analytics, SVM helps detect spam emails, classify customer feedback, and identify patterns in large datasets. Its versatility makes it a valuable tool in AI and machine learning applications across different domains.
When to Use Support Vector Machines
SVM is best suited for datasets with clear margins of separation and moderate size. In Data Science workflows, it is often chosen when accuracy is more important than speed. Professionals use SVM alongside other machine learning algorithms to achieve better results, especially when working with structured data in Python environments.
Conclusion: Importance of SVM in Modern Analytics
Support Vector Machines continue to play a significant role in the evolution of Data Science and AI. Their ability to handle complex classification tasks makes them a preferred choice in many machine learning projects. By combining SVM with tools like Power BI and programming languages such as Python, organizations can unlock valuable insights and enhance their data analytics capabilities.