Introduction to Random Forest in Machine Learning
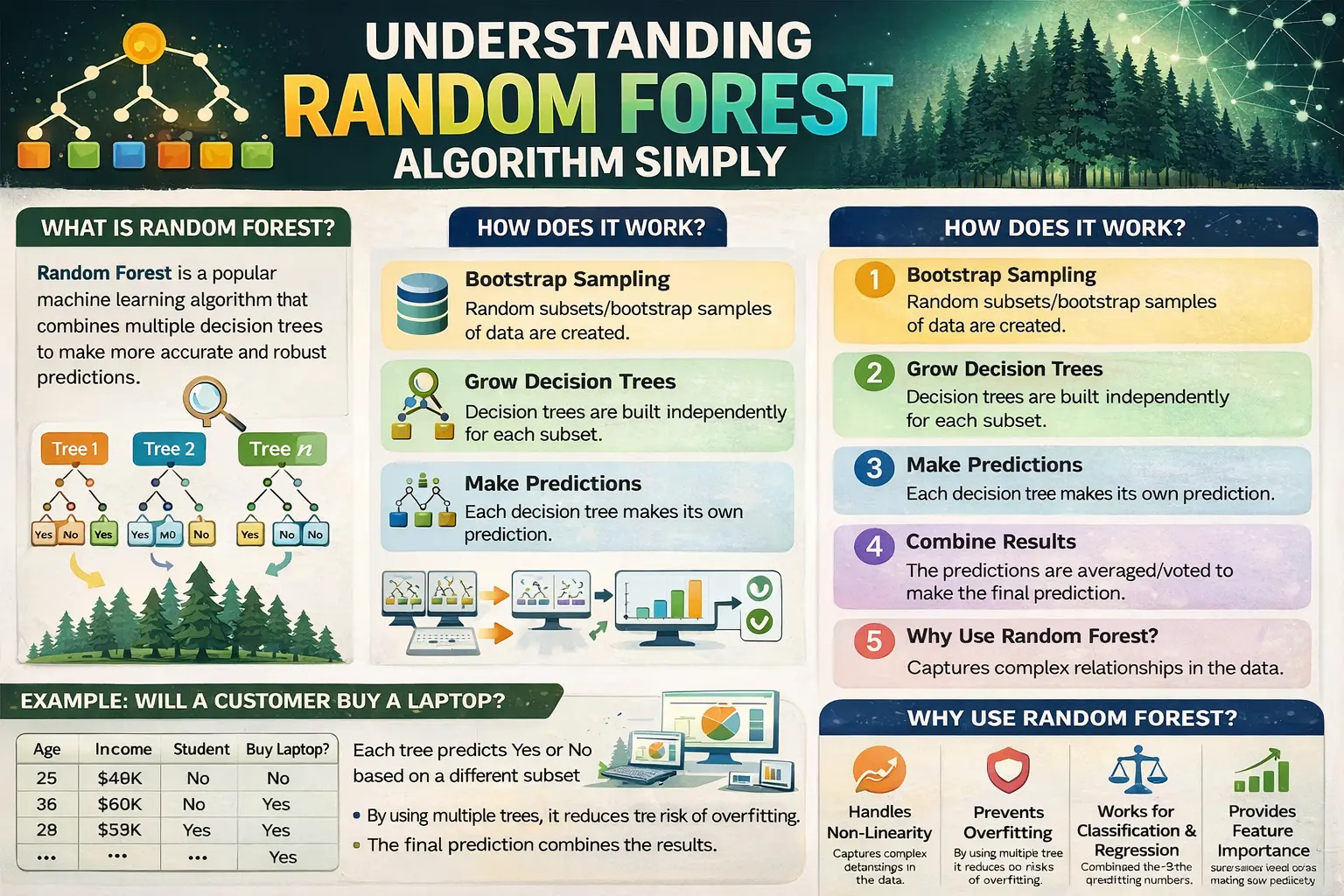
Random Forest is a powerful and widely used algorithm in machine learning that builds multiple decision trees and combines their results. In fields like Data Science and AI, it is known for its accuracy and ability to handle complex datasets. It is especially useful for beginners who want a reliable model without deep technical complexity, using Python.
What is the Random Forest Algorithm
Random Forest is an ensemble learning method that creates many decision trees and merges their outputs to produce a final result. In data analytics, this approach improves prediction accuracy by reducing errors that may occur in a single decision tree model.
How Random Forest Works Step by Step
The algorithm works by selecting random samples from the dataset and building decision trees for each sample. Each tree makes its own prediction, and the final output is based on majority voting or averaging. In machine learning, this method helps in achieving better performance and stability compared to individual models.
Key Features of Random Forest
Random Forest has several important features, such as randomness, multiple tree creation, and aggregation of results. In Data Science, these features help in improving accuracy and reducing overfitting. The algorithm can handle both classification and regression tasks effectively.
Advantages of the Random Forest Algorithm
One of the biggest advantages of Random Forest is its high accuracy and robustness. In AI applications, it performs well even with large and complex datasets. It also reduces the risk of overfitting, making it a preferred choice in many data analytics projects.
Limitations of Random Forest
Despite its strengths, Random Forest has some limitations. It can be slower compared to simpler algorithms and may require more computational resources. In machine learning, it may also be harder to interpret compared to a single decision tree, especially for beginners.
Implementation Using Python
Random Forest can be easily implemented using Python libraries like Scikit-learn. With simple code, beginners can train and test models on datasets. This makes it an ideal algorithm for those learning Data Science and exploring practical applications.
Real-World Applications of Random Forest
Random Forest is widely used in industries for tasks like fraud detection, recommendation systems, and medical diagnosis. In AI systems, it helps in making accurate predictions based on large datasets. Its versatility makes it valuable in data analytics projects.
Comparison with Decision Trees
While decision trees are simple and easy to understand, Random Forest improves their performance by combining multiple trees. In Data Science, this leads to more accurate and reliable predictions. It is often used when a single tree does not provide sufficient accuracy.
Integration with Data Visualization Tools
The results of Random Forest models can be visualized using different tools. In Power BI, data processed using this algorithm can be presented through dashboards and reports. This helps in better understanding and communication of insights in data analytics.
Best Practices for Using Random Forest
To achieve the best results, it is important to tune parameters such as the number of trees and the depth of each tree. In machine learning, proper parameter tuning improves model performance and efficiency. Regular testing and validation are also important steps in Data Science workflows.
Conclusion: Why Random Forest is Important
Understanding Random Forest is essential for anyone working in Data Science, AI, Power BI, machine learning, data analytics, and Python. It provides a powerful way to handle complex data and improve prediction accuracy. By learning this algorithm, beginners can strengthen their foundation in machine learning and build effective data-driven solutions.