Introduction to Overfitting and Underfitting in Machine Learning
In the field of machine learning, building a model that performs well on new and unseen data is the ultimate goal. However, many beginners face two common problems known as overfitting and underfitting. These issues directly impact how accurately a model can make predictions. With the growing importance of Data Science and machine learning, understanding these concepts is essential for developing reliable AI systems.
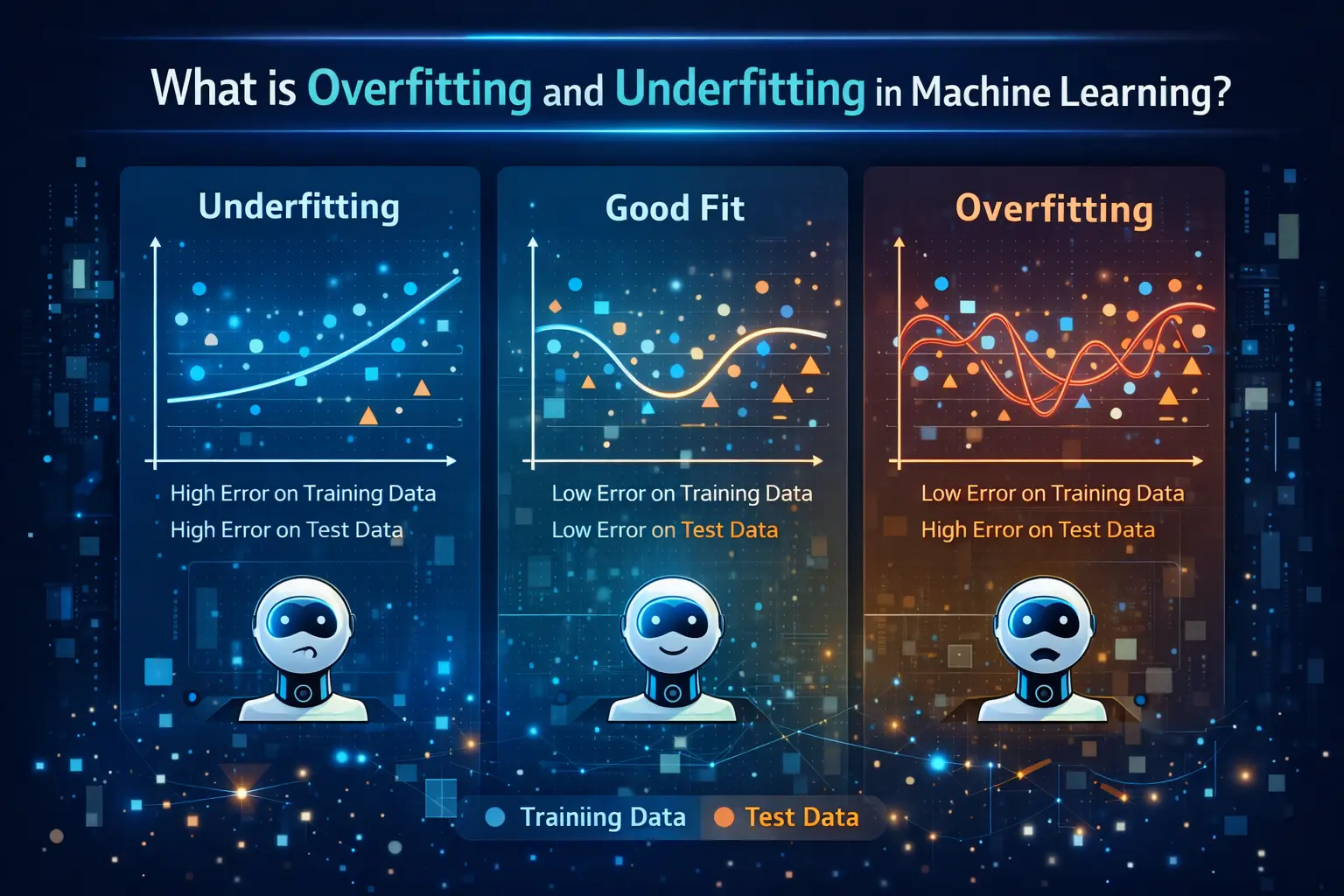
What is Overfitting?
Overfitting occurs when a machine learning model learns the training data too well, including its noise and minor details. Instead of capturing general patterns, the model memorizes the dataset. As a result, it performs extremely well on training data but fails to generalize when tested on new data. In practical applications of AI and data analytics, overfitting can lead to poor decision-making and unreliable predictions.
What is Underfitting?
Underfitting is the opposite of overfitting. It happens when a model is too simple to capture the underlying patterns in the data. In this case, the model performs poorly on both training and test data because it has not learned enough from the dataset. In Data Science projects, underfitting often occurs when the model lacks complexity or when insufficient data is used during training.
Key Differences Between Overfitting and Underfitting
The main difference between overfitting and underfitting lies in how the model learns from the data. Overfitting models are overly complex and capture unnecessary details, while underfitting models are too simple and miss important patterns. In machine learning and AI systems, finding the right balance between these two extremes is crucial for achieving optimal performance.
Causes of Overfitting
Overfitting can occur due to several reasons, such as using a highly complex model, having too many features, or training the model for too long. Limited or noisy data can also contribute to this issue. In Data Science and machine learning, improper data handling and a lack of validation techniques can increase the chances of overfitting.
Causes of Underfitting
Underfitting usually happens when the model is too basic or when important features are not included. It can also occur if the training process is stopped too early or if the dataset is too small. In AI and data analytics, underfitting limits the model’s ability to learn meaningful relationships, resulting in inaccurate predictions.
How to Detect Overfitting and Underfitting
Detecting these issues involves comparing the model’s performance on training data and test data. If a model performs well on training data but poorly on test data, it is likely overfitting. If it performs poorly on both, it is underfitting. In Data Science workflows, techniques like cross-validation and performance metrics help identify these problems effectively.
Techniques to Prevent Overfitting
There are several methods to reduce overfitting in machine learning models. These include using more training data, applying regularization techniques, reducing model complexity, and using dropout in neural networks. In AI and data analytics, these strategies help create models that generalize better and provide more accurate results.
Techniques to Fix Underfitting
To address underfitting, the model needs to be made more complex or trained for a longer time. Adding more features, selecting better algorithms, and improving data quality can also help. In Data Science and machine learning, fine-tuning the model ensures that it learns the necessary patterns without becoming too simplistic.
Real-World Impact of Overfitting and Underfitting
In real-world applications, both overfitting and underfitting can have serious consequences. For example, in healthcare, an overfitted model may fail to diagnose new patients correctly, while an underfitted model may miss critical patterns in medical data. In AI-powered business systems, these issues can affect decision-making, customer experience, and overall performance.
Importance of Balance in Machine Learning Models
Achieving the right balance between overfitting and underfitting is key to building successful machine learning models. This balance ensures that the model performs well on both training and unseen data. With the help of Data Science, AI, and machine learning techniques, professionals can fine-tune models to achieve optimal accuracy and reliability.
Conclusion
Overfitting and underfitting are fundamental challenges in machine learning that every beginner must understand. They highlight the importance of model selection, data quality, and proper training techniques. As the demand for Data Science, AI, and data analytics continues to grow, mastering these concepts will help in building efficient and trustworthy models that perform well in real-world scenarios.