Introduction to Data Pipelines in Data Science
A data pipeline is one of the most important concepts for beginners entering the field of modern technology. It refers to the process of collecting, processing, and moving data from one system to another in a structured way. In today’s digital environment, organizations rely heavily on Data Science, AI, Power BI, machine learning, and data analytics to transform raw data into valuable insights. Understanding how data pipelines work is the first step toward building efficient and scalable data-driven solutions.
What is a Data Pipeline?
A data pipeline is a series of steps that automate the flow of data from its source to a destination, such as a database or analytics tool. It ensures that data is consistently collected, cleaned, and delivered for analysis. With the growing demand for Data Science, AI, Power BI, machine learning, and data analytics, data pipelines have become essential for handling large volumes of data efficiently. They help reduce manual work and improve the speed and reliability of data processing.
Importance of Data Pipelines in Data Science
Data pipelines play a critical role in ensuring that data is available, accurate, and ready for analysis. Without a proper pipeline, data scientists would spend most of their time cleaning and organizing data instead of analyzing it. In the world of Data Science, pipelines enable the smooth integration of different tools and systems. They also support real-time data processing, which is essential for businesses that rely on quick decision-making.
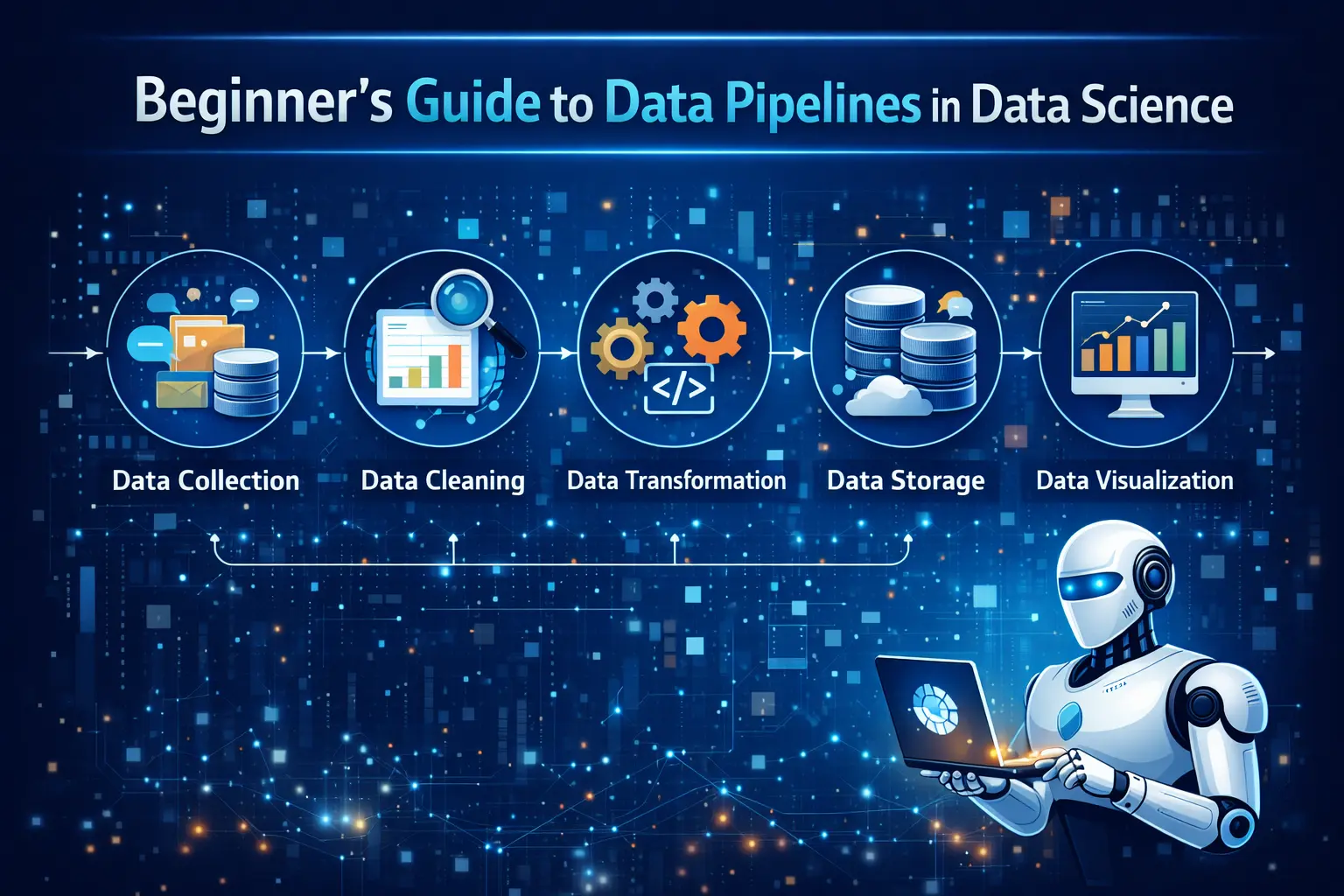
Key Components of a Data Pipeline
A typical data pipeline consists of several key components, including data sources, data ingestion, data processing, storage, and data visualization. Data sources can include databases, APIs, or IoT devices. Ingestion involves collecting data, while processing includes cleaning and transforming it. Tools used in Data Science, AI, Power BI, machine learning, and data analytics often rely on these components to ensure seamless data flow. Each component plays a vital role in maintaining the efficiency of the pipeline.
Types of Data Pipelines
There are mainly two types of data pipelines: batch processing and real-time processing. Batch processing handles large volumes of data at scheduled intervals, while real-time processing deals with continuous data streams. Both types are widely used in Data Science, AI, Power BI, machine learning, and data analytics, depending on business needs. Choosing the right type of pipeline depends on how quickly the data needs to be processed and analyzed.
Steps to Build a Data Pipeline
Building a data pipeline involves several steps, starting with identifying data sources and defining the objectives. The next step is data ingestion, followed by data cleaning and transformation. After processing, the data is stored in a suitable format and made available for analysis. In Data Science, AI, Power BI, machine learning, and data analytics, these steps ensure that data is reliable and ready for decision-making. Proper planning and execution are key to building an effective pipeline.
Tools Used for Data Pipelines
There are many tools available for building and managing data pipelines. Popular tools include Apache Airflow, Apache Kafka, Talend, and cloud-based solutions like AWS Data Pipeline. These tools help automate workflows and manage data efficiently. In Data Science, AI, Power BI, machine learning, and data analytics, such tools are widely used to handle complex data operations and ensure smooth data movement across systems.
Benefits of Using Data Pipelines
Data pipelines offer numerous benefits, including improved efficiency, scalability, and data accuracy. They automate repetitive tasks and reduce the chances of human error. Businesses using Data Science, AI, Power BI, machine learning, and data analytics can make faster and more informed decisions with the help of well-structured pipelines. Additionally, pipelines enable organizations to handle large datasets without compromising performance.
Challenges in Data Pipelines
Despite their advantages, data pipelines come with certain challenges. Managing data quality, handling large volumes of data, and ensuring security can be difficult. Integration between different systems may also create complexities. In Data Science, AI, Power BI, machine learning, and data analytics, overcoming these challenges requires proper planning, the right tools, and skilled professionals. Addressing these issues is essential for maintaining a reliable pipeline.
Real-World Applications of Data Pipelines
Data pipelines are used in various industries for different purposes. In e-commerce, they help track customer behavior and improve recommendations. In finance, they are used for fraud detection and risk analysis. Healthcare organizations use pipelines to manage patient data and improve treatment outcomes. These applications highlight the importance of Data Science, AI, Power BI, machine learning, and data analytics in solving real-world problems through efficient data handling.
Future of Data Pipelines in Data Science
The future of data pipelines looks promising as technology continues to evolve. With the rise of automation and cloud computing, pipelines are becoming more advanced and easier to manage. In Data Science, AI, Power BI, machine learning, and data analytics, future pipelines will focus on real-time processing, scalability, and integration with AI systems. This will enable businesses to gain faster insights and stay competitive in a data-driven world.
Conclusion
A strong understanding of data pipelines is essential for anyone starting a career in data science. They form the backbone of data processing and ensure that information flows smoothly from source to insight. With the growing importance of Data Science, AI, Power BI, machine learning, and data analytics, mastering data pipelines can open up numerous career opportunities. By learning how to build and manage pipelines, beginners can take a significant step toward becoming skilled data professionals.