Introduction to Supervised vs Unsupervised Learning
Machine learning is one of the most important branches of modern technology, and understanding its core concepts is essential for beginners. Among these concepts, supervised and unsupervised learning are the two main types of learning methods used in building intelligent systems. In the world of Data Science and AI, these approaches help machines learn patterns from data and make predictions or decisions without explicit programming.
What is Supervised Learning?
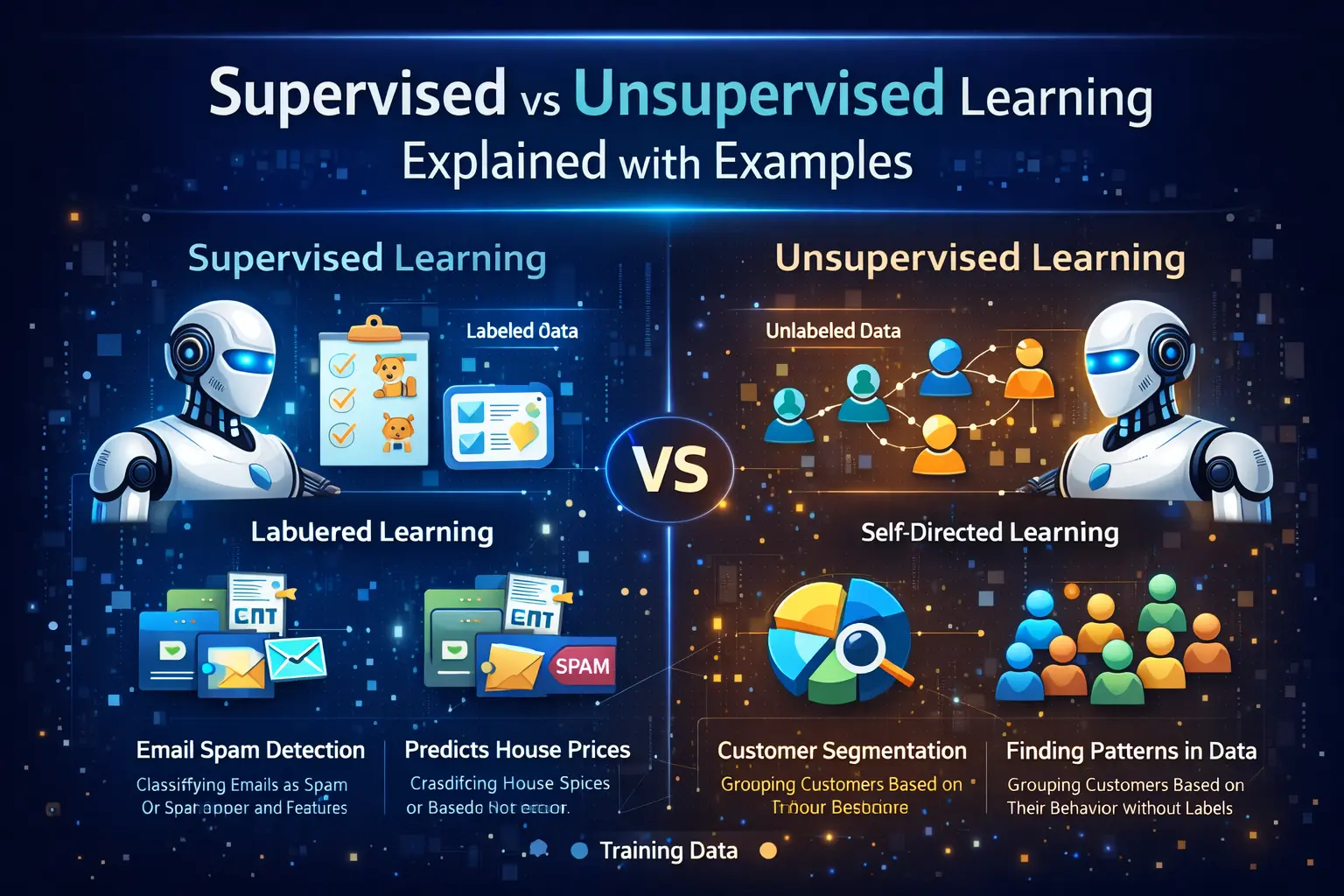
Supervised learning is a type of machine learning where the model is trained using labeled data. This means that each input in the dataset is paired with the correct output. The model learns by comparing its predictions with the actual results and improving over time. In machine learning applications, supervised learning is widely used for tasks such as classification and regression, making it a key part of data analytics workflows.
Examples of Supervised Learning
A common example of supervised learning is email spam detection. In this case, the model is trained using emails labeled as “spam” or “not spam.” Another example is predicting house prices based on features like location, size, and number of rooms. In Data Science projects, these types of problems are solved using algorithms like linear regression and decision trees, which learn directly from labeled datasets.
What is Unsupervised Learning?
Unsupervised learning, on the other hand, works with unlabeled data. The model is not given any predefined output and must find patterns or structures within the data on its own. This approach is useful when there is no clear answer available in the dataset. In AI and machine learning, unsupervised learning is often used for clustering and association tasks.
Examples of Unsupervised Learning
A popular example of unsupervised learning is customer segmentation. Businesses use this method to group customers based on their behavior, preferences, or purchase history. Another example is anomaly detection, where the model identifies unusual patterns in data. In data analytics, these techniques help organizations uncover hidden insights and improve decision-making.
Key Differences Between Supervised and Unsupervised Learning
The main difference between supervised and unsupervised learning lies in the type of data used. Supervised learning relies on labeled data, while unsupervised learning works with unlabeled data. In machine learning systems, supervised learning is more straightforward as it has a clear objective, whereas unsupervised learning requires the model to explore and discover patterns independently. Both methods are essential in Data Science and serve different purposes.
Advantages of Supervised Learning
Supervised learning offers high accuracy when trained with quality data. It is easier to evaluate because the correct answers are already known. In AI applications, this method is widely used in image recognition, speech recognition, and predictive analytics. Its structured approach makes it a reliable choice for many business use cases.
Advantages of Unsupervised Learning
Unsupervised learning is powerful when dealing with large amounts of unstructured data. It helps discover hidden patterns that may not be immediately obvious. In Data Science and data analytics, this approach is useful for exploratory data analysis and identifying trends without prior knowledge. It is especially valuable in situations where labeled data is not available.
Challenges in Both Learning Methods
Both supervised and unsupervised learning come with their own challenges. Supervised learning requires large amounts of labeled data, which can be time-consuming and expensive to obtain. Unsupervised learning, on the other hand, may produce results that are difficult to interpret. In AI and machine learning, selecting the right approach depends on the problem and the available data.
Real-World Applications
Supervised and unsupervised learning are widely used across industries. In healthcare, supervised learning helps in disease prediction, while unsupervised learning is used for patient segmentation. In finance, supervised models detect fraud, while unsupervised models identify unusual transactions. These applications highlight the importance of Data Science, AI, and data analytics in solving real-world problems.
Choosing the Right Approach
Choosing between supervised and unsupervised learning depends on the nature of the problem and the type of data available. If labeled data is available and the goal is prediction, supervised learning is the best choice. If the goal is to explore data and find patterns, unsupervised learning is more suitable. In machine learning projects, understanding these differences helps in selecting the most effective method.
Conclusion
Supervised and unsupervised learning are fundamental concepts that form the backbone of machine learning. Both approaches have unique strengths and are used in different scenarios to solve complex problems. With the growing demand for Data Science, AI, machine learning, and data analytics, mastering these techniques is essential for building intelligent systems and advancing in the field.